
Introduction to Large Language Models
How They Actually Work, and Why Most Explanations Miss the Point

TL;DR — Introduction to Large Language Models (LLMs)
Large Language Models create value not by generating text, but by compressing cognitive labor inside existing enterprise workflows. Their economic impact emerges when they are embedded into systems where data, accountability, and decision rights already exist. As an interface layer between humans and complex software, LLMs reduce interpretation costs, coordination friction, and execution time.
The primary beneficiaries are incumbent platforms that control workflows and distribution. In CRM, analytics, cybersecurity, and creative software, LLMs strengthen moats by increasing productivity, deepening user lock-in, and lowering switching costs rather than disrupting incumbents. AI reinforces advantages where trust, data ownership, and integration matter.
However, LLMs remain probabilistic systems with clear boundaries. Risks such as hallucination, overconfidence, and lack of true reasoning require human oversight and domain constraints. AI is most effective when used as an assistive layer, not an autonomous decision-maker.
From an investment perspective, LLMs are not a reset of competitive dynamics. They are a leverage mechanism that amplifies well-positioned platforms and exposes structurally weak ones. AI does not flatten enterprise markets. It sharpens them.

If you haven’t explored our previous research, you may revisit some of our earlier due diligence reports and thematic notes below. Each piece reflects the same thesis-driven framework we apply across every investment case.
For a closer look at how these principles translate into real positions, explore the 👉 Sample Portfolio — a demonstration of thesis-driven allocation and disciplined compounding.


How They Actually Work, and Why Most Explanations Miss the Point
Large Language Models have quickly become one of the most discussed technologies of the past few years. They are often described as intelligent, reasoning systems capable of understanding language, generating ideas, and even replacing human judgment.

Most of these descriptions are misleading.
To understand what LLMs truly are and what they are not, it is useful to step away from hype, demos, and surface-level explanations, and instead focus on the underlying mechanism that governs how these systems behave.
This article does not attempt to teach you how to build a model. It aims to explain, at a conceptual level, what LLMs are actually doing, why they appear intelligent, and where their real limitations lie.
What an LLM Really Does
At its core, a large language model performs a single task: It predicts the next token.
A token can be a word, part of a word, or a symbol. Given a sequence of tokens as input, the model assigns probabilities to all possible next tokens and selects one based on that distribution.
![Introduction to Large Language Models: Everything You Need to Know for 2025 [+Resources] | Lakera – Protecting AI teams that disrupt the world.](https://substackcdn.com/image/fetch/$s_!rDQa!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9d1457b8-0c3c-4b24-970c-074cb3556101_868x394.png "Introduction to Large Language Models: Everything You Need to Know for 2025 [+Resources] | Lakera – Protecting AI teams that disrupt the world.")
There is no understanding in the human sense. There is no internal model of truth. There is no awareness of meaning.
An LLM does not know that the sky is blue. It has learned, from vast amounts of data, that given the sequence “The sky is”, the token “blue” has a high statistical likelihood of appearing next.
This distinction is critical.
What looks like reasoning is, in reality, the repeated application of conditional probability across extremely high-dimensional representations of language.
From Text to Tokens
Before prediction can occur, text must be transformed into a format the model can process.

User input is first tokenized. Words are broken down into standardized units that the model has seen during training. These tokens are then converted into numerical vectors known as embeddings.
Embeddings are not words. They are coordinates in a high-dimensional space. In this space, tokens that tend to appear in similar contexts are positioned closer together.
At this stage, the model still does not understand language. It has only converted symbols into numbers.
The apparent intelligence emerges later.
Context, Not Memory
One of the most common misconceptions is that LLMs store or recall information in the way humans do.
They do not.
LLMs operate entirely within a context window. Everything the model knows at a given moment comes from the tokens currently provided to it. There is no persistent memory unless explicitly engineered outside the model.
The key innovation that allows LLMs to perform well is attention.
Attention mechanisms allow the model to evaluate how strongly each token in the input relates to every other token. This enables the model to weigh context dynamically rather than process text sequentially in a rigid order.
This is why LLMs can handle long sentences, resolve references, and maintain coherence across paragraphs.
Not because they understand meaning, but because they are extremely good at modeling relationships between symbols across context.
Generation Is Just Repeated Prediction
Once a token is selected, it is appended to the input, and the process repeats.
Prediction becomes generation.

Each step depends entirely on previous tokens, including those the model generated itself. Over time, this recursive process produces paragraphs, arguments, code, and explanations that appear deliberate and structured.
This illusion of intentionality is one of the most powerful and misleading aspects of LLMs.
The model is not planning. It is not reasoning toward a goal. It is simply continuing a sequence in a statistically coherent way.
Why LLMs Started Working Only Recently
Language modeling is not new. Neural networks capable of processing text have existed for decades.
What changed was scale.
Three factors converged:
First, data. The availability of large, diverse text corpora allowed models to observe language across countless domains, styles, and contexts.
Second, compute. Modern accelerators made it feasible to train models with hundreds of billions of parameters.
Third, architecture. Transformer-based models enabled efficient handling of long-range dependencies through attention mechanisms.
None of these breakthroughs alone was sufficient. Together, they pushed language modeling past a threshold where fluent, coherent output became possible.
This is less a story of intelligence and more a story of infrastructure.
How Language Models Actually Create Business Value
Large Language Models do not generate economic value simply by producing text. Their impact comes from being embedded into existing enterprise systems where decisions, workflows, and accountability already exist.

This distinction matters. In most corporations, the bottleneck is not information scarcity, but the cost of interpretation, coordination, and execution. LLMs reduce these costs by acting as an interface layer between humans and complex systems, compressing cognitive labor rather than replacing it.
The companies best positioned to benefit are therefore not pure AI providers, but incumbent platforms that already control data, distribution, and workflow ownership.
In enterprise software, this dynamic is clearly visible. Platforms such as Salesforce are not using LLMs to “automate sales.” Instead, language models operate inside the CRM workflow to summarize customer histories, surface risks in pipelines, and reduce the time spent on administrative tasks. The economic benefit is incremental but persistent: higher productivity per user, deeper product embedding, and lower switching probability. AI does not weaken the moat. It thickens it.
A similar pattern appears in data analytics and decision platforms such as Palantir. In complex organizations, data is abundant but insight is scarce. LLMs function as translators between natural language and analytical systems, allowing non-technical decision-makers to interact directly with complex data environments. The value does not come from better models, but from lowering the cost of extracting insight from systems that already exist. This shifts AI from a research tool into an operational one.
In cybersecurity, the role of LLMs is even more constrained. Companies like CrowdStrike operate in environments where false positives and uncontrolled automation carry real risk. Language models are therefore used to assist analysts rather than replace them. They summarize threat activity, correlate signals, and explain incidents across technical and executive audiences. This improves response speed and organizational clarity without removing human oversight. Trust is preserved, which is essential in security workflows.
Creative software presents a different, but equally instructive case. Adobe’s integration of AI is not about replacing designers or automating creativity. Instead, generative tools accelerate iteration, assist with ideation, and reduce friction in production workflows. Crucially, this happens within a framework of licensing, attribution, and professional standards. For enterprise and professional users, reliability and compliance matter more than novelty. AI strengthens Adobe’s position as creative infrastructure rather than disrupting it.
Across these examples, a consistent structure emerges. LLMs create durable value when they are embedded into existing workflows, constrained by enterprise rules, and paired with proprietary data. Standalone intelligence is easily commoditized. Integrated intelligence is not.
This is why AI, contrary to popular narratives, often reinforces incumbent advantages. The firms that already control workflows, customer relationships, and trust are the ones that convert AI capabilities into sustained economic returns.
From an investment perspective, LLMs should not be viewed as a reset button for competitive dynamics. They are a leverage mechanism. They amplify the strengths of well-positioned platforms and expose the weaknesses of those without distribution or integration.
AI does not flatten the enterprise landscape. It sharpens it.
Where LLMs Are Strong
LLMs excel in domains where:
Patterns are dense
Language is structured
Feedback loops are weak or delayed
Errors are tolerable
They are powerful tools for summarization, drafting, translation, classification, and ideation.
In many professional workflows, they function best as productivity layers rather than autonomous decision-makers.
They reduce friction. They compress time. They expand surface area.
They do not replace judgment.
Where LLMs Break Down
LLMs struggle when:
Ground truth matters
Feedback is sparse or delayed
Incentives are misaligned
Precision is critical
They hallucinate because they are not designed to verify facts. They fail silently because probability does not encode confidence.
This is why LLMs appear reliable until they are not.
Risks, Hallucination, and the Boundaries of AI
Despite their growing usefulness, Large Language Models operate within clear and often misunderstood boundaries. Their most visible limitation is hallucination: the tendency to generate confident but incorrect outputs when faced with ambiguity, incomplete data, or poorly constrained prompts. This is not a temporary bug. It is a structural feature of probabilistic models trained to predict language, not to verify truth.

In enterprise settings, this risk is mitigated not by “better models,” but by governance and design. High-value deployments constrain LLMs with retrieval systems, deterministic rules, audit trails, and human-in-the-loop oversight. The goal is not autonomy, but assistance. When AI operates inside well-defined workflows with clear accountability, hallucination becomes a manageable risk rather than a fatal flaw.
More broadly, AI systems lack agency, judgment, and responsibility. They do not understand consequences, incentives, or context beyond what is encoded in data and constraints. This creates a natural boundary: AI can accelerate cognition, but it cannot own decisions. In regulated industries such as finance, healthcare, and security, this distinction is critical. Outputs may inform actions, but accountability remains human.
There is also a strategic boundary. As models become more capable, marginal improvements increasingly commoditize. What remains defensible is not intelligence itself, but integration, data ownership, and trust. Enterprises that mistake AI for a replacement of judgment risk operational failure. Those that treat it as a force multiplier within disciplined systems tend to extract durable value.
In this sense, the future of AI is less about removing humans from the loop and more about tightening the loop. The most successful implementations respect the limits of the technology, embed it within institutional controls, and align it with human incentives.
AI is powerful precisely because it is constrained.
Understanding where those constraints lie is not a technical exercise. It is a strategic one.
A Useful Mental Model
A practical way to think about LLMs is this: They are extremely sophisticated autocomplete systems operating over a compressed representation of human language.

When deployed with appropriate constraints, oversight, and domain boundaries, they are transformative.
When treated as thinking agents, they become dangerous.
Final Reflection
The most important insight about LLMs is not how impressive they are.
It is how narrow their core function remains, despite their broad applications.
Understanding this gap between appearance and mechanism is essential for anyone making decisions about deploying, regulating, investing in, or relying on these systems.
They are infrastructure.
And like all infrastructure, their value depends less on what they can do in isolation and more on how thoughtfully they are integrated into larger systems.
Disclaimer
This publication is provided for informational and educational purposes only and does not constitute investment advice, a recommendation, or an offer to buy or sell any securities. All opinions expressed are based on publicly available information believed to be reliable at the time of writing, but accuracy and completeness cannot be guaranteed. Past performance is not indicative of future results. Investing involves risk, including the potential loss of principal. Readers should conduct their own due diligence and consult a qualified financial advisor before making investment decisions.
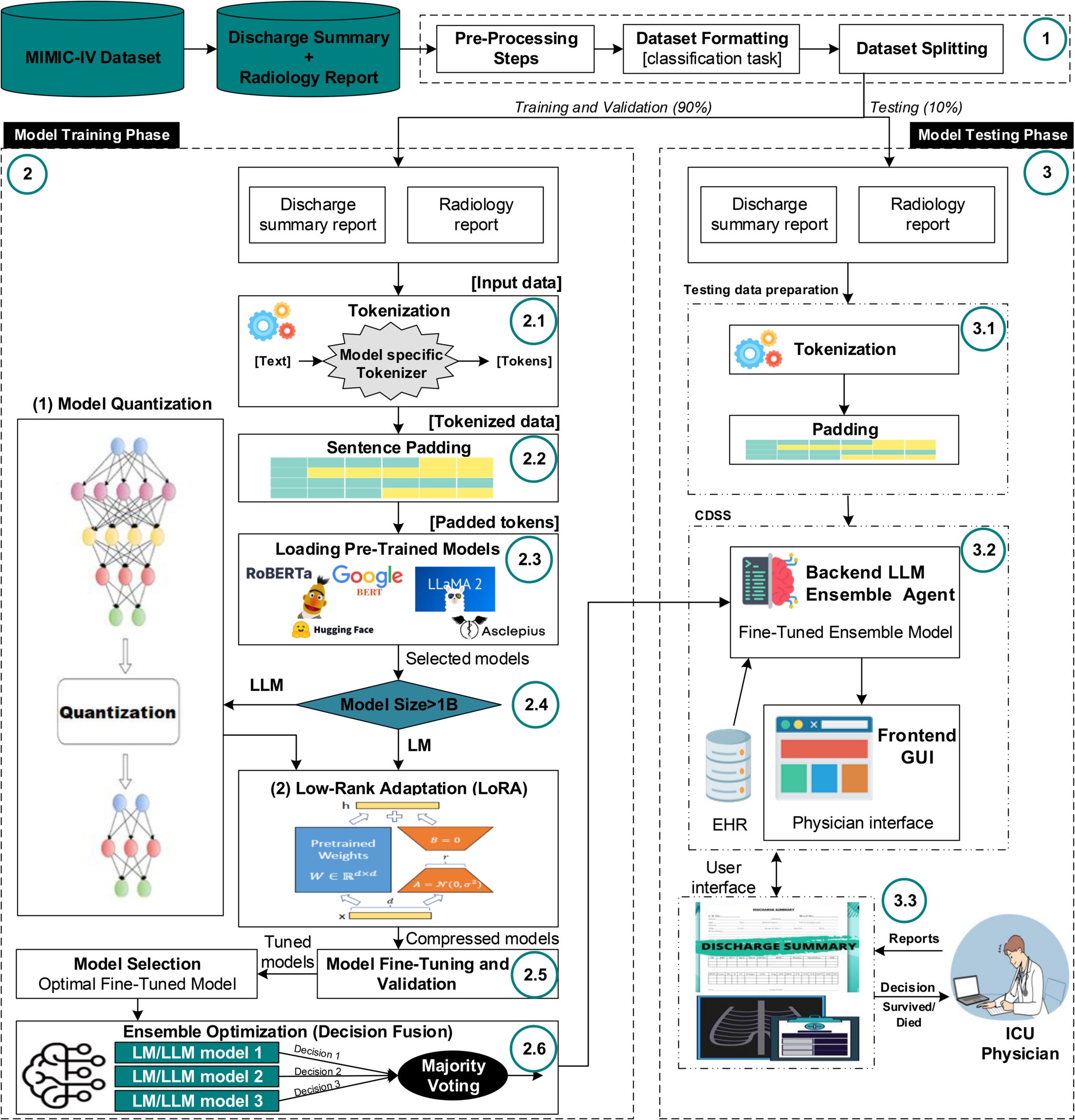
Reference:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0332134
Statistical engines in workflows = value. Standalone intelligence = hype.
I run an agent in production workflows - email processing, content scheduling, data analysis. Works because it's embedded, not standalone.
The reasoning debate misses this. LLMs don't need to "think" - they need to fit into existing systems reliably.
Wrote about the bubble: https://thoughts.jock.pl/p/ai-bubble-living-inside